À l’automne et au printemps 2016 se tenaient respectivement aux États-Unis la conférence internationale sur le web sémantique, et ici à Montréal la conférence sur le World Wide Web, auxquelles j’ai eu l’occasion d’assister. L’une des importantes conclusions que je retiens de ces conférences, c’est que le web et le web sémantique vont s’imposer de plus en plus dans nos vies et qu’elles feront partie intégrante de la nouvelle économie mondiale.
Je m’intéresse au web sémantique depuis 2005 et je constate, à mon grand étonnement, qu’en dehors du milieu universitaire, on parle très peu de cette technologie. Signe de ce silence, aucune offre d’emploi n’est affichée ici au Québec dans ce domaine, alors qu’en Europe et aux États-Unis les offres abondent. C’est notamment pour ouvrir le débat sur le web sémantique que j’ai préparé ce billet.
Note historique — Article de 2016. Ce texte a été rédigé lors de la conférence WWW 2016 à Montréal. Certaines références technologiques reflètent l’état de l’art de l’époque (IoT sémantique, offres d’emploi, adoption institutionnelle). Une mise à jour 2026 est disponible en fin d’article.
Cet article présente les sept raisons pour lesquelles le web sémantique devrait être au centre d’une politique du numérique :
- Le web sémantique est une technologie mûre, éprouvée, ouverte, non-propriétaire, gratuite, libre de droits et sécuritaire
- Les informations, les données et les métadonnées sont interopérables
- Il génère des bénéfices puisqu’il se fonde sur le principe de réutilisabilité des vocabulaires
- Le web sémantique est une technologie au centre de l’économie du savoir
- Le web sémantique offre les principes de gouvernance aux données ouvertes
- Le web sémantique est un médium de valorisation d’une culture
- Le web sémantique est une plateforme d’intelligence artificielle et un moteur de l’innovation
1 — Une technologie mûre, ouverte et standardisée par le W3C
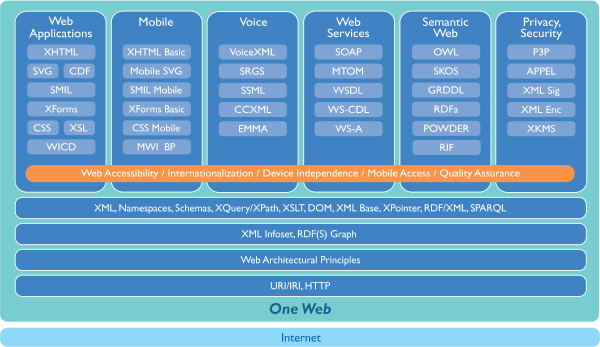
Le web sémantique, comme l’ensemble des technologies du web (voir la pile technologique ci-dessous), est une technologie normalisée par le W3C, l’organisme à but non lucratif dont la mission est de normaliser et standardiser les technologies sur le web.
Comme pour le (X)HTML, le XML, le CSS, le SVG, le SOAP, etc., les vocabulaires RDF, RDFS, OWL et SKOS — qui sont au cœur du web sémantique — font partie des standards qui permettent d’exploiter la puissance du web.
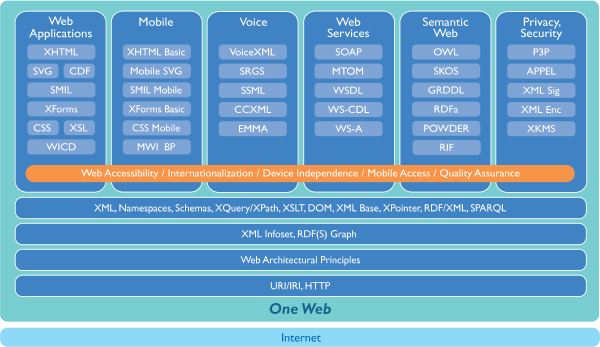
Pile technologique du web. Référence : https://www.w3.org/2004/10/RecsFigure-Smaller.png
{kind=link}
À sa base, l’Internet est la technologie réseau qui supporte le Web. Les quatre premières couches (URI, Web Architectural Principles, XML/RDF(S) Graph et XML-NameSpaces, etc.) servent de support aux technologies s’adressant à des usages spécifiques : application web, mobilités, voix, service web, web sémantique, sécurité et vie privée. On y constate que les principaux vocabulaires du web sémantique (RDF(S) et SPARQL) sont à la base de la pile technologique du web.
Note : dans cette figure, on distingue bien l’Internet du Web, et on y constate qu’en fait, le web est une application de l’Internet.
C’est donc dire qu’une politique numérique qui envisage d’utiliser le web en tant que véhicule de l’information doit nécessairement envisager d’utiliser la technologie du web sémantique.
2 — Les informations, les données et les métadonnées sont interopérables
2.1 — Lire une information de façon interopérable
Un principe fondateur du web est l’interopérabilité. Ce principe stipule que la réalisation d’une action sur le web doit se dérouler de façon indépendante de l’architecture technologique nécessaire pour son exécution. Par exemple, pour l’action de « lire une information », cette lecture sera web si elle se réalise indépendamment du navigateur utilisé (Internet Explorer, Firefox, Safari, etc.) et indépendamment de la technologie du serveur qui diffuse l’information (Apache, IIS, etc.). Dans ce contexte, on dira que la notation qui permet de coder l’information est interopérable. La notation interopérable de base dans le web est le HTML.
2.2 — Traiter des données interopérables
Voici l’exemple d’une information que nous pourrions lire sur le web : « La ville de Montréal est une ville intelligente ». Est-ce que cet énoncé constitue des données sur le web ? Sous cette forme, la réponse est non. Pour un logiciel, un tel énoncé est considéré comme une chaîne de caractères sans signification. C’est donc dire qu’à priori, aucun traitement automatique ne peut découler de cet énoncé.
Pour déclencher un traitement automatique, il est nécessaire de coder un signifiant aux termes de l’énoncé. Par exemple, indiquer que : « Ville de Montréal » est une « Ville », qu’une « ville intelligente » est une sorte de « Ville » qui a la particularité d’être « Intelligente ». C’est de cette codification du signifiant que surgit l’aspect « sémantique » du web — et c’est à cette condition que l’on peut parler de données sur le web.
Ainsi, pour être une donnée sur le web, l’information doit répondre à au moins trois conditions :
- L’information doit être codée avec une notation utilisable par une machine
- Le signifiant doit aussi être codé avec une notation utilisable par une machine
- Les notations utilisées pour coder l’information et son signifiant doivent être interopérables
Les notations interopérables à la base du web sémantique sont : le Resource Description Framework (RDF), le Resource Description Framework Schema (RDFS) et le Web Ontology Language (OWL).
Dans une politique du numérique, l’interopérabilité des données est une particularité importante puisqu’elle permet de définir des enjeux et des principes indépendants des technologies.
3 — Le web sémantique génère des bénéfices puisqu’il se fonde sur le principe de réutilisabilité des vocabulaires
Il a été vu précédemment que la technologie du web sémantique permet de coder le signifiant d’une donnée. Dans le vocabulaire du web sémantique, le fichier qui entrepose « un signifiant » est nommé Ontologie. L’ontologie est pour ainsi dire la base de données du web, puisqu’elle déclare les données et la structure des données qu’elle utilise.
Étant donné que le web est un espace de partage de points de vue, il est aussi permis dans le web de diffuser des ontologies qui permettent de coder la signification du point de vue. C’est ce qui est appelé un vocabulaire. Par exemple :
- Le vocabulaire de Dublin Core permet de coder des données décrivant des ressources bibliographiques
- L’ontologie Financial Industry Business Ontology (FIBO) s’adresse spécifiquement à la codification de données financières
- Friend Of A Friend (FOAF), l’ontologie au cœur des réseaux sociaux, permet de déclarer que l’ami de mon ami est aussi mon ami
Le web foisonne de vocabulaires dans divers domaines de connaissances qui sont réutilisables pour nos applications informatiques locales. Il s’agit dès lors d’une économie considérable de temps dévolu à la conception d’ontologies. Encore mieux : être le concepteur d’une ontologie exploitée par d’autres ressources du web est une occasion unique de rayonner dans le web et un moyen efficace d’influencer la perception globale par notre point de vue sur un domaine.
Plusieurs pays dans le monde, notamment la France, les États-Unis, l’Angleterre et l’Italie, ont saisi cet enjeu et ont fait du web sémantique une priorité technologique.
4 — Le web sémantique : une technologie au centre de l’économie du savoir
On trouve au centre d’une économie du savoir le cycle de gestion de la connaissance, qui se décompose en 5 actions : Repérer, Préserver, Valoriser, Partager, Actualiser. Pour chacune d’elles, le web sémantique y joue un rôle particulier :
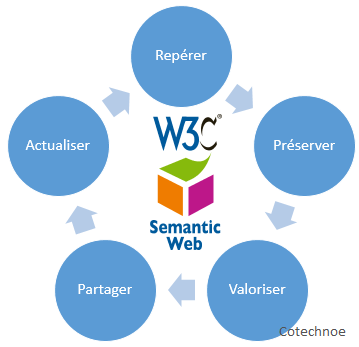
- Repérer — Le web sémantique abonde en outils qui permettent de localiser l’information. Google, Bing, Yahoo, etc. sont des outils de recherche qui utilisent entre autres le web sémantique pour indexer le web.
- Préserver — La préservation de la connaissance est assurée par l’ontologie. Comme indiqué plus haut, l’ontologie emmagasine les données décrivant quelque chose ainsi que la structure qui permet de décrire la donnée.
- Valoriser — L’interopérabilité de l’ontologie permet à des clients web de venir capturer les données diffusées et de réaliser des traitements spécifiques qui sont guidés par la sémantique de la donnée codée dans l’ontologie.
- Partager — L’ontologie (ou le graphe de connaissances) qui contient la connaissance (donnée + structure de données) est partagée sur le web avec l’aide d’un serveur web (par ex. : Apache ou IIS) auquel on ajoute des services web particuliers pour faciliter l’accès aux données par des requêtes web (voir le langage SPARQL).
- Actualiser — Tous changements de contenu sont visibles du web. Les agents du web qui perçoivent un changement dans un contenu local s’ajustent à ce contenu. De même, un contenu local s’adaptera à un changement de contenu dans le web. Une politique du numérique qui incorpore le web sémantique stimule l’économie du savoir en stimulant les interconnexions entre les données du web.
5 — Le web sémantique offre les principes de gouvernance aux données ouvertes
Un enjeu économique et d’éthique important des gouvernements est la mise en ligne de données citoyennes sur le web. Cependant, sans une diffusion synchronisée de la signification de la donnée, les efforts de mise en ligne sont inutiles puisque difficilement traitables par les robots du web. Une adhésion aux cinq étoiles du web de données ouvertes et liées (Linked Open Data — LOD), dont le web sémantique est la technologie porteuse, est très utile pour sauver la mise.
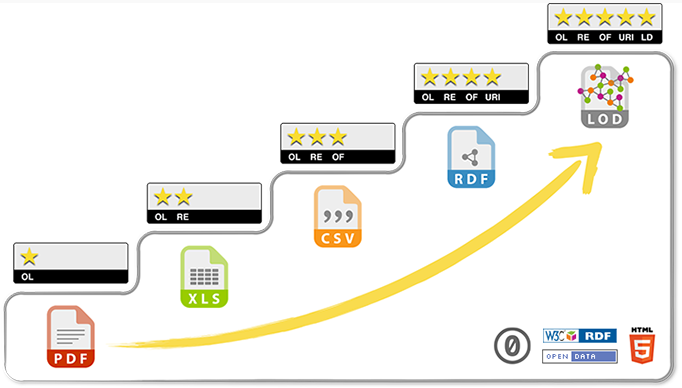
Selon le principe des cinq étoiles, une donnée web est ouverte et liée si elle répond aux cinq conditions :
| Étoile | Condition | Description |
|---|---|---|
| ★ | Licence ouverte (OL) | La donnée est libre de droits |
| ★★ | Lisible par un ordinateur (RE) | La donnée est lisible et traitable par un logiciel |
| ★★★ | Format de données ouvert (OF) | La structure est dans une notation interopérable |
| ★★★★ | URI pour désigner les ressources | La donnée est accessible à partir d’un URI |
| ★★★★★ | Lier les données (Linked Data) | La donnée est diffusée via des services web permettant son utilisation par les agents du web |
Pour le gouvernement ouvert et la ville intelligente, le web de données ouvertes et liées offre une plateforme mondialement normalisée et standardisée pour la diffusion de données interopérables et la captation de données sur le web.
6 — Le web sémantique est un médium de valorisation de la culture d’une société
Le web est une grande bibliothèque de contenus d’œuvres culturelles entreposées dans des ressources web de différents formats : vidéo, images, audio, textuels, etc. Comme pour une bibliothèque qui maintient des fiches bibliographiques décrivant ses œuvres et qui facilite la recherche, le web dispose de la technologie du web sémantique pour identifier par les métadonnées les œuvres qu’il contient. L’œuvre du web décrite par des métadonnées est facilement indexée et localisée par les outils de recherche du web. En revanche, une œuvre sans métadonnées est comme le livre sans fiche — elle est perdue dans la masse des œuvres et pratiquement jamais consultée.
Au Québec, la culture est une industrie importante. Elle est créative, productive et distinctive. En ce moment, les œuvres, surtout musicales, peuvent être repérées par des outils tels qu’iTunes ou Google Play. Mais ces outils de repérage sont des outils propriétaires à des entreprises qui décident des œuvres à indexer ou non. On ne peut donc parler ici d’une réelle interopérabilité des ressources, puisque l’accès à ces ressources est totalement régi par des politiques privées de gouvernance et d’accès.
Le web sémantique offre une solution économique pour décrire la métadonnée interopérable d’une ressource culturelle et elle contient les caractéristiques nécessaires pour répondre aux exigences d’une politique publique et démocratique de gouvernance dans la diffusion des œuvres sur le web. Une connaissance approfondie des technologies du web sémantique permettra à la culture québécoise d’avoir sa place dans le web — sans le web sémantique, les ressources culturelles occuperont dans le web une place déterminée par les autres acteurs du web.
7 — Le web sémantique : une plateforme d’intelligence artificielle et un moteur d’innovation
Il a été précédemment abordé que l’ontologie est le fichier informatique au centre du web sémantique. L’ontologie entrepose la donnée et le schéma de la donnée pour une diffusion dans le web. Dans le paradigme de l’approche symbolique en intelligence artificielle, les données et leur structure sont emmagasinées dans ce qui est appelé une base de connaissances. Cette base de connaissances, traitée par un moteur d’inférence, permet de conclure à de nouvelles connaissances. Par exemple, la base de faits décrivant que « Snoopy est un Beagle, et qu’un Beagle est une sorte de Chien » permettra au moteur d’inférence de conclure que « Snoopy est un Chien ».
Or, une spécificité importante de l’ontologie est qu’elle a les mêmes caractéristiques qu’une base de connaissances. Pour le spécialiste de l’IA symbolique, l’ontologie du web sémantique est une base de connaissances apte à entreposer des énoncés logiques et apte à être traitée par un moteur d’inférence, aussi appelé raisonneur.
7.1 — Le web sémantique dans l’Internet des objets de la ville intelligente
L’Internet des objets (IoT — Internet of Things), ces objets connectés dans la ville qui fournissent des données au sujet d’événements physiques (niveau d’ozone, de bruits, la température, etc.), prend une place de premier rang dans le paradigme de la ville intelligente. En ce moment et dans la plupart des cas, les objets connectés n’utilisent pas le web sémantique — ce qui implique que les données produites sont propriétaires et non interopérables. À terme, cette situation engendrera des silos de masses de données IoT qui seront de plus en plus difficiles à gérer.
L’introduction des technologies du web sémantique dans le module logiciel de l’objet connecté permettra deux choses :
- Interopérationnaliser les données fournies par l’objet connecté
- Rendre l’objet connecté intelligent — par la technologie du web sémantique, l’objet connecté sera l’hôte d’une ontologie servant de base de connaissances à un raisonneur. Chaque objet connecté pourra donc prendre des décisions et en informer le central des objets. Mieux encore, il sera en mesure d’informer par le web les autres objets connectés pour ainsi former des écosystèmes d’objets intelligents et connectés par le web.
À ce jour, l’utilisation du web sémantique pour l’Internet des objets est un projet d’étude important du W3C. Des ontologies de vocabulaires spécifiques aux objets connectés sont en cours de création et de mise en œuvre. L’introduction du web sémantique dans la partie logicielle de l’objet connecté ouvrira des opportunités d’innovation dans l’utilisation de données interopérables pour le Big Data et par l’utilisation de l’intelligence artificielle pour l’exploitation, la gestion et le contrôle des objets connectés.
En conclusion
Il a été présenté sept raisons pour introduire la technologie du web sémantique au centre d’une politique du numérique. Nous aurions pu en élaborer beaucoup plus. Mais la véritable raison d’introduire cette technologie au centre d’une politique du numérique est la suivante : il ne pourrait y avoir de politique du numérique sans y introduire une politique du web. Aussi, il ne peut y avoir de politique du web si nous n’avons pas une place dans le web. Et la seule technologie qui permet d’avoir accès à l’ensemble des ressources du web est le web sémantique.
Finalement, la question n’est pas de savoir si nous devons ou ne devons pas utiliser le web sémantique, mais plutôt : quand déciderons-nous de l’utiliser ? Plusieurs pays dans le monde ont compris les enjeux liés à cette technologie et y investissent massivement. À nous de décider du moment où nous souhaiterons adhérer à cette économie du futur.
Mise à jour 2026 — Ce que la décennie a confirmé
Dix ans après la rédaction de cet article, les sept raisons tiennent toujours — mais le paysage a profondément évolué.
Les graphes de connaissances sont devenus mainstream. Google, Amazon, Microsoft et Meta opèrent des graphes de connaissances massifs en production. Schema.org — vocabulaire issu de l’initiative commune Google/Bing/Yahoo/Yandex — est aujourd’hui intégré dans la quasi-totalité des CMS et des plateformes e-commerce. Les bibliothèques et archives nationales (BnF, Library of Congress, Bibliothèque nationale du Québec) ont adopté des solutions SPARQL pour leurs catalogues.
LLM + graphes de connaissances : GraphRAG. La limitation majeure des grands modèles de langage (hallucinations, traçabilité des sources) trouve une réponse directe dans la combinaison avec les ontologies RDF/OWL. Microsoft Research a publié en 2024 GraphRAG, une architecture qui ancre les réponses des LLM dans un graphe de connaissances structuré — exactement le paradigme décrit en raison 7. L’IA symbolique et le web sémantique ne s’opposent plus aux approches connexionnistes : ils les complètent.
W3C Web of Things (WoT). La raison 7.1 anticipait l’interopérabilité sémantique des objets connectés. Le W3C a publié en 2020 la recommandation Web of Things Architecture, qui formalise exactement ce modèle : chaque objet connecté expose une Thing Description en JSON-LD (format RDF), rendant ses données interopérables et traçables sur le web.
Ce qui a moins bien vieilli. L’adoption institutionnelle au Québec est restée marginale. Les offres d’emploi en web sémantique pur sont remplacées par des postes en knowledge engineering, data mesh, et ontology engineering — même réalité, vocabulaire différent. L’argument « gratuit et libre de droits » de la raison 1 s’est complexifié : les outils ouverts (Apache Jena, Protégé, Fuseki) coexistent avec des plateformes commerciales (Stardog, Ontotext, Amazon Neptune).
La question de 2026 n’est plus « quand ? » mais « comment ? » Les organisations qui intègrent leurs données dans des graphes de connaissances structurés obtiennent un avantage mesurable en qualité des réponses LLM, en gouvernance des données et en interopérabilité. C’est maintenant un enjeu opérationnel, pas seulement stratégique.
Michel Héon, Ph.D. Docteur en informatique cognitive Président fondateur de Cotechnoe
Article originalement publié le 24 mai 2016 sur le blog Web sémantique de Cotechnoe.